I learned a lot digging into this which I'll summarize below. TLDR: yes, it seems like the NPS4 NUMA topology is accurate. Nodes 1/2 do have lower-latency access to memory than nodes 0/3. This is surprising to me because I'd always seen the 3960x/3970x diagrammed like this:
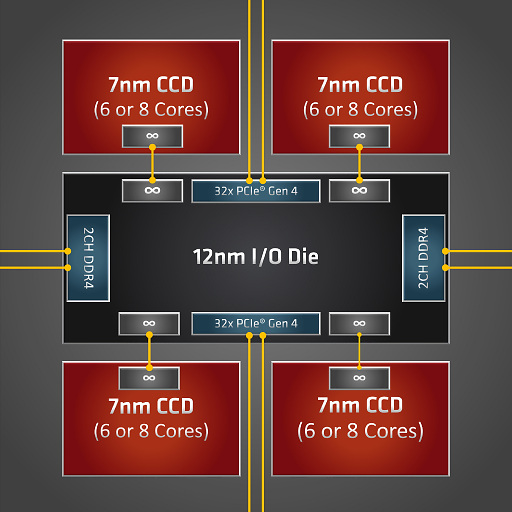
The package has 4 CCDs arranged into quadrants, each with two 3-core (3960x) or 4-core (3970x) CCXs. From this diagram it seems like the two CCDs on the left should have equal access to the memory channels on that side. So, not one channel per CCD like I was thinking, but two channels shared between two CCDs, making NPS2 seem most reasonable.
However, a more detailed diagram from WikiChip shows some asymmetry:
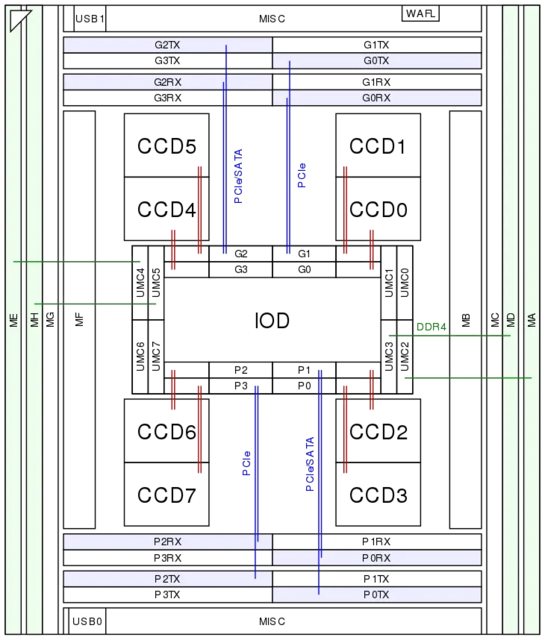
CCD0 (top right) is connected to the I/O die by a GMI2 link (red lines). Right next to it are two memory controllers (UMC0&1), but these are not connected to any memory channels. In contrast, CCD2 underneath it is right next to UMC2/3, which are connected to memory channels. It's conceivable that CCD2 has lower memory latency than CCD1.
Can we measure it? One tool for this is the Intel Memory Latency Checker. Let's try it!
# tar xf mlc_v3.10.tgz
# sysctl vm.nr_hugepages=4000
vm.nr_hugepages = 4000
# ./Linux/mlc --latency_matrix
Intel(R) Memory Latency Checker - v3.10
malloc(): corrupted top size
[1] 18377 IOT instruction (core dumped) ./Linux/mlc --latency_matrix
Uh, okay then, let's try the previous version:
# tar xf ~/Downloads/mlc_v3.9a.tgz
# sysctl vm.nr_hugepages=4000
vm.nr_hugepages = 4000
# ./Linux/mlc --latency_matrix
Intel(R) Memory Latency Checker - v3.9a
Command line parameters: --latency_matrix
Using buffer size of 600.000MiB
Measuring idle latencies (in ns)...
Numa node
Numa node 0 1 2 3
0 - 98.8 108.1 -
1 - 93.3 111.9 -
2 - 112.3 93.2 -
3 - 107.6 97.9 -
This confirms it! Same-node latency is ~93ns, and node 1↔2 latency is ~112ns, but node 0↔1 and 2↔3 latency is in between at ~98ns. Interestingly, nodes 0/3 worst-case latency is slightly better than nodes 1/2 at ~108ns. This makes sense looking at the diagram, as CCD0 is slightly closer to UMC4/5 than CCD2. Bandwidth has a similar story:
# ./Linux/mlc --bandwidth_matrix
Intel(R) Memory Latency Checker - v3.9a
Command line parameters: --bandwidth_matrix
Using buffer size of 100.000MiB/thread for reads and an additional 100.000MiB/thread for writes
Measuring Memory Bandwidths between nodes within system
Bandwidths are in MB/sec (1 MB/sec = 1,000,000 Bytes/sec)
Using all the threads from each core if Hyper-threading is enabled
Using Read-only traffic type
Numa node
Numa node 0 1 2 3
0 - 33629.4 31791.2 -
1 - 34332.5 31419.5 -
2 - 31193.1 34266.8 -
3 - 32077.3 33799.3 -
What this seems to mean is that some cores on a 3960x (and presumably 3970x) are slightly privileged with regard to memory latency and bandwidth. I'd be curious to see the results for a 3990x -- does e.g. CCD1 perform similarly to CCD0?

